|
David Minnen Email | CV | Scholar | Google Research | Photography |

|
|
(see
my CV for a full list of publications)
| |
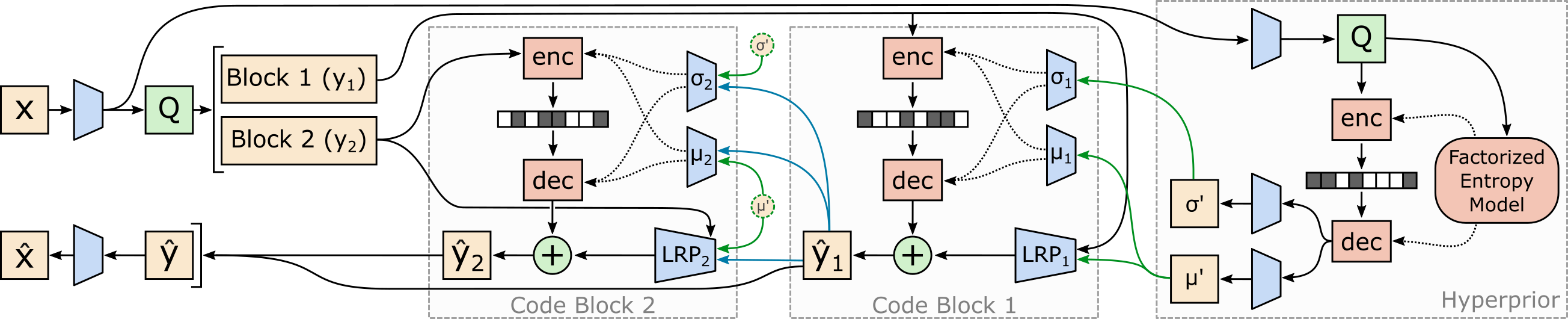 |
David Minnen and Saurabh Singh Better runtime and rate-distortion performance for learned image compression. We improve the entropy model with latent residual prediction and channel-wise conditioning instead of spatial context. |
 |
Johannes Ballé, Philip A. Chou, David Minnen, Saurabh Singh, Nick Johnston, Eirikur Agustsson, Sung Jin Hwang, and George Toderici A review of learned image compression framed as nonlinear transform coding (NTC). This paper analyzes rate-distortion performance using simple sources and natural images, introduces a novel variant of entropy-constrained vector quantization and a method for learning multi-rate models, and analyzes different forms of stochastic optimization techniques for compression models. |
 |
Eirikur Agustsson, David Minnen, Nick Johnston, Johannes Ballé, Sung Jin Hwang, and George Toderici Learns "compressible flow" within an end-to-end optimized model for video compression. Optical flow is typically a 2D vector field representing motion. We generalize this to a 3D representation that holds spatial offsets plus a scale-space parameter. Larger scale values lead to more blurring before warping. The model learns to predict a small scall coupled with accurate flow and a large scale when accurate flow is not possible (or is too expensive to code relative to the target bit rate). |
 |
Johannes Ballé, Nick Johnston, and David Minnen Avoids floating point non-determinism for entropy model parameters predicted by deep networks. Non-determinism typically doesn't matter for deep networks, but it is catastrophic for entry coding. |
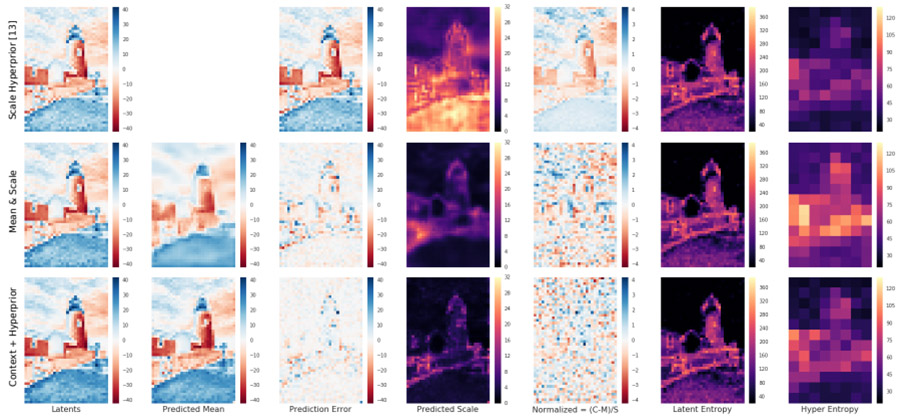 |
David Minnen, Johannes Ballé, and George Toderici Combines a hyperprior with spatial context to improve entropy modeling for learned image compression. By mixing forward and backward-adaptation, we achieve a new state-of-the-art for rate-distortion performance with neural compression models. |
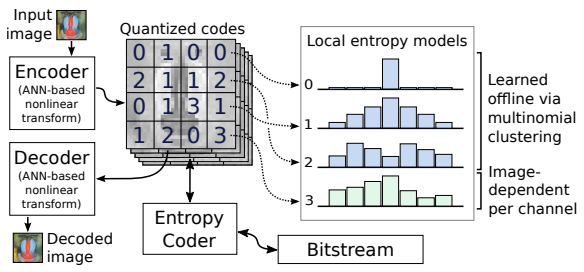 |
David Minnen, George Toderici, Saurabh Singh, Sung Jin Hwang, and Michele Covell We learn a dictionary of entropy models and allow the encoder to select the best distribution for each channel and each spatial tile. If none of the distributions match the local data, the encoder transmits a custom histogram. This spatially local and image-dependent modeling improves rate-distortin peroformance over earlier models and avoids floating point non-determinism that can break entropy models predicted on the fly. |
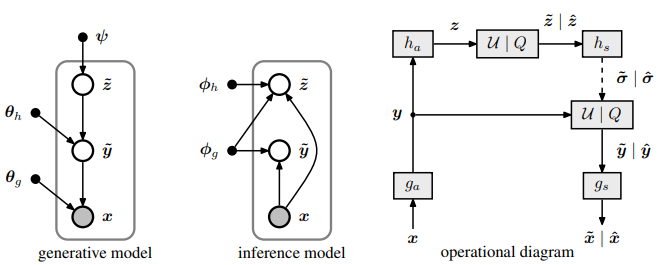 |
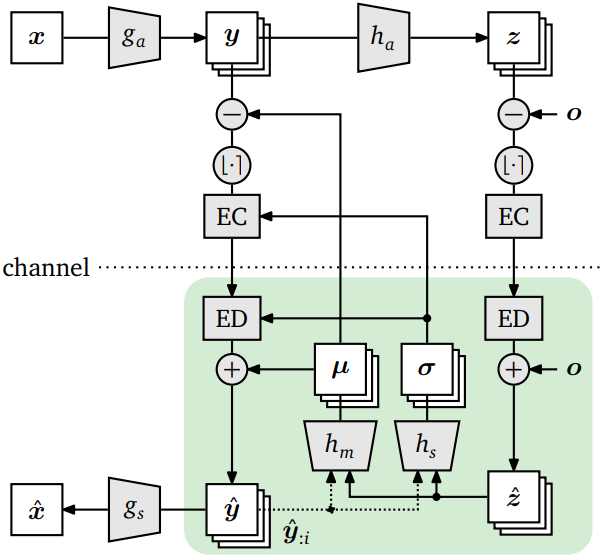
Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston This model is the first to introduce a hyperprior for end-to-end optimized image compression with deep networks. The model learns a non-linear transform from pixels to a quantized latent space, which is jointly optimized with a hyperprior that predicts the parameters of the entropy model used to code the latents. |
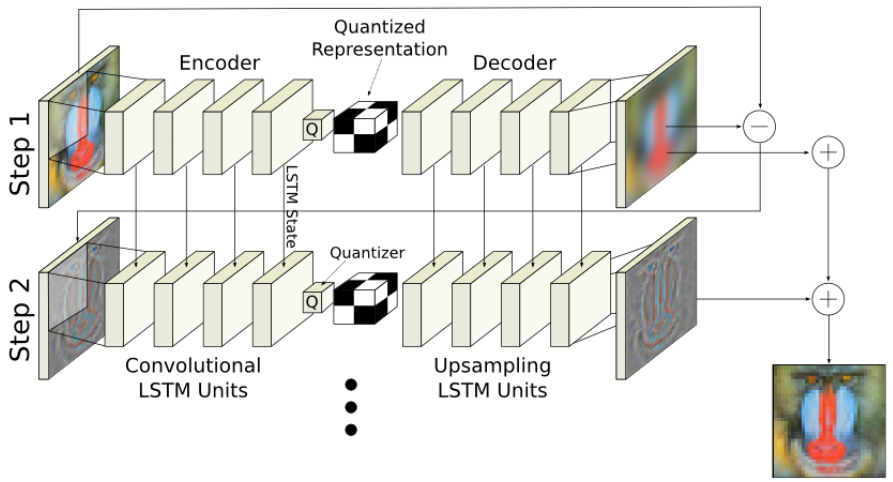 |
Nick Johnston, Damien Vincent, David Minnen, Michele Covell, Saurabh Singh, Troy Chinen, Sung Jing Hwang, Joel Shor, and George Toderici Our team's best compression network based on recurrent neural network. I developed the spatially adaptive bit rate (SABR) component that allowed the encoder to adapt the local bit rate to the image content, which improves overall rate-distortion performance. |
|
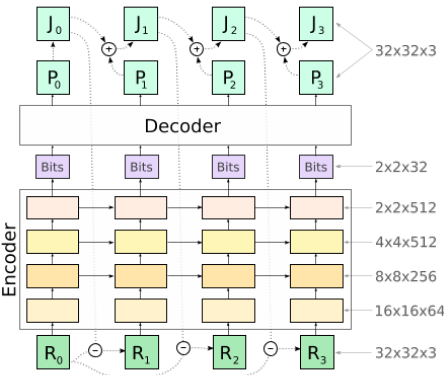
David Minnen, George Toderici, Michele Covell, Troy Chinen, Nick Johnston, Joel Shor, Sung Jin Hwang, Damien Vincent, and Saurabh Singh Deep neural networks are used for image intra-prediction. Each tile is predicted from neighboring tiles in the causal context, and then the residual is coded separately. By using a progressive model based on recurrent networks, the encoder can spatially adapt the bit rate to improve the overall rate-distortion performance. |
|
[site layout adapted from Jon Barron]
| |